Deep Research 项目研究
Table of contents
本文研究 AI 应用领域中的 Deep Research 方向,主要涉及下面三个开源项目
LangChain Open Deep Research
本文分析基于 Git commit b419df8d33b4f39ff5b2a34527bb6b85d0ede5d0 版本
架构
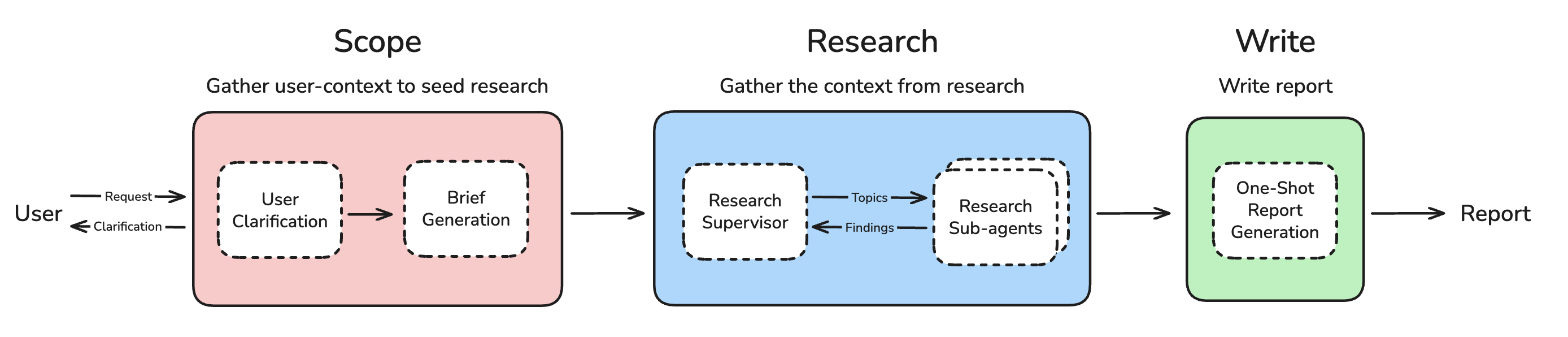 该项目将 任务划分成了3个阶段
该项目将 任务划分成了3个阶段
- Scope:明确研究范围
- Research:核心模块,执行研究任务
- Write:输出最终报告
Graph Node
Research Node
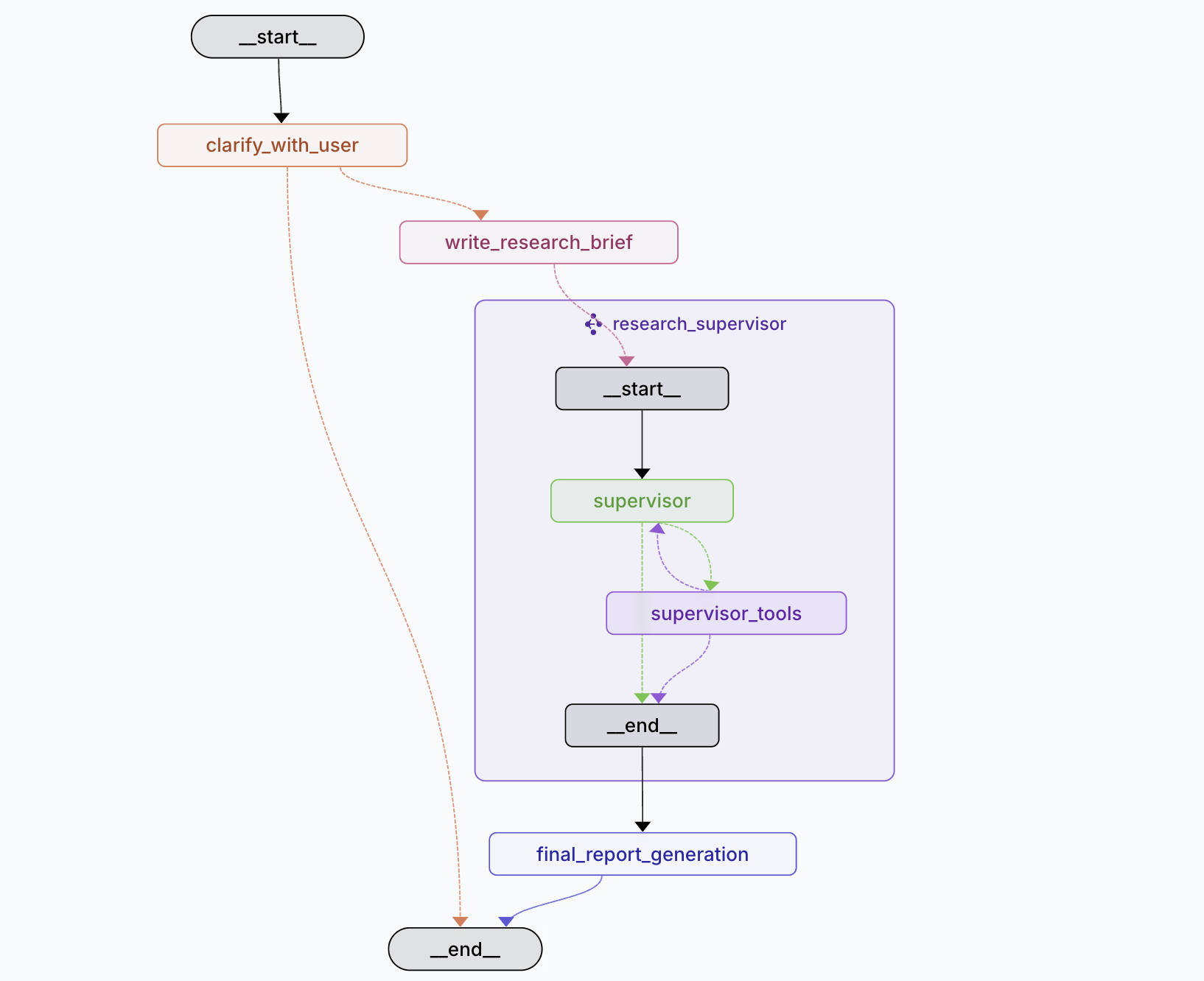
- Scope Phase 包含两个节点:
- clarify_with_user node: 当用户的任务比较模糊,缺失足够的上下文信息时,会和用户确认收集额外信息,以得到一个相对清晰的任务。
- write_research_brief node: 根据与用户之前的交互(包括问题澄清,在先前的研究报告上进一步探索等)生成一个研究简报。生成简报主要是为了减少噪音,整合上下文,后续的研究过程会在这个简报上进行。
- Research Phase 这是一个 multi agent 的实现:
- Supervisor Sub Graph:确定研究简报是否可以分解为独立的子主题,并将任务分配给具有独立上下文窗口的子代理
- supervisor node
- supervisor_tools node:工具节点,包含下面工具
- Think Tool:反思工具,在执行 ConductResearch 前会进行思考现在有了什么信息,还需要哪些信息等,用于规划后续 ConductResearch 行为
- ConductResearch Tool :调用 Research Sub-Agents 进行检索与研究,支持并发调以调研不同的 topic
- ResearchComplete Tool:虚拟工具,作为 Research Phase 终结的条件(除了该工具,还有研究迭代次数限制,无工具调用工具会终止 Research 流程)
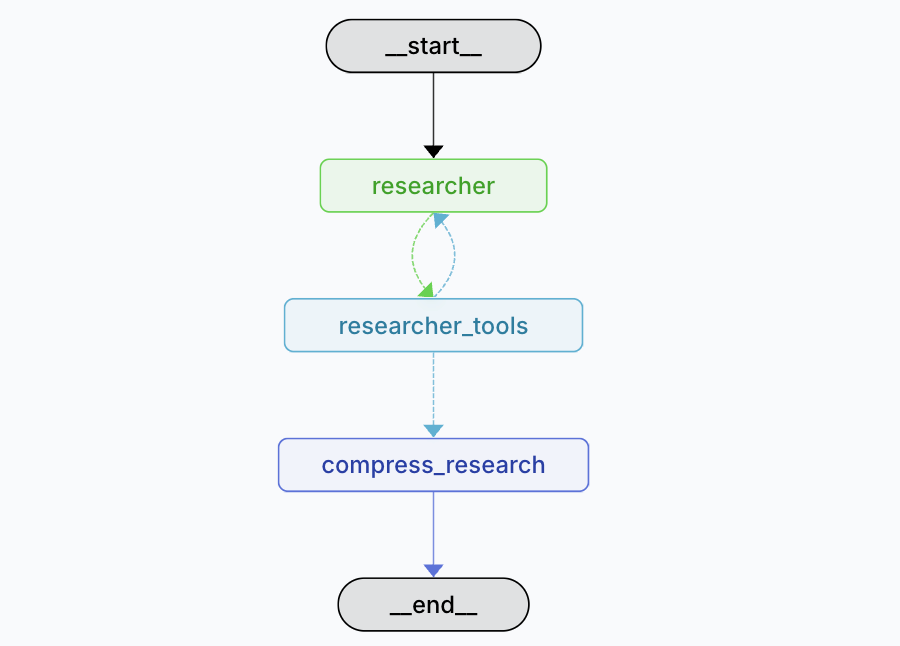
- Researcher Sub Graph :根据 supervisor 分配的主题进行研究
- researcher node :
- researcher_tools node: 工具节点,包含下面工具
- Think Tool: 和 Supervisor 类似,也有一个 ThinkTool 来规划后续 search 流程
- Search Tools:搜索工具,内部支持了 TAVILY 搜索, OpenAI 和ANTHROPIC 的 Web Search 功能
- MCP Tools:支持通过 MCP 协议动态扩展 Researcher 的工具与能力
- ResearchComplete Tool: 作为 Researcher 终结的条件
- compress_research_node: 当子代理完成任务后,会将收集到的信息进行进一步撰写详细且干净的回答返回给 supervisor
- Supervisor Sub Graph:确定研究简报是否可以分解为独立的子主题,并将任务分配给具有独立上下文窗口的子代理
- Write Phase
- final_report_generation node:当 supervisor 收集到足够的信息结束研究任务后,该节点结合研究简报撰写最后输出的报告
LLM
该项目支持了 OpenAI、ANTHROPIC 和 Google 系列的 LLM(也可以扩展使用 Open Router 或者本地模型) ,同时允许在不同的节点配置使用不同的模型去处理任务 默认配置如下
- Summarization:
openai:gpt-4.1-mini - Research:
openai:gpt-4.1 - Compression:
openai:gpt-4.1 - Final Report Model:
openai:gpt-4.1
可以根据不同阶段的任务特性选择不同的模型,例如 Research 阶段选择推理能力更好的模型,报告撰写选择文字能力更好的模型等。
Think Tool
这里介绍一下 Think Tool,它运用在 supervisor 和 researcher node 中。 Think Tool 是在 Agent 执行任务过程中,添加一个停下来思考是否拥有继续前进所需全部信息的步骤。这在执行长串工具调用或与用户进行长时间多步骤对话时特别有帮助。它的原理类似人类反思的操作,思考目前已有的信息、之前执行过的操作与目标任务之前的偏差,决策或者纠正后续的动作。 Think Tool 虽然名称是叫工具,但它并不像其它工具(如搜索工具)一样执行获取信息等额外操作。本质上它只是将反思想法的想法添加到 LLM 的上下文内,引导后续的 LLM 决策。
Prompt 中用于指引 LLM 思考的部分
<Show Your Thinking>
After each search tool call, use think_tool to analyze the results:
- What key information did I find?
- What's missing?
- Do I have enough to answer the question comprehensively?
- Should I search more or provide my answer?
</Show Your Thinking>
更多关于 Think Tool 的信息可以参考 # The “think” tool: Enabling Claude to stop and think in complex tool use situations 这篇文章,里面提到了使用 Think Tool 的收益以及如何使用 Think Tool 。
Prompt & 上下文工程
该项目使用的 Prompt 都在 prompts 这个文件,这里不展开描述。
这里着重讲一下上下文中的一些策略。
上下文隔离
Multi Agent 除了可以并发进行研究任务提高效率外,另外一个好处就是隔离了上下文,这是一个常见的有效管理上下文的手段。每个 Sub Agent 在给定的 topic 下工作,并不携带主线程之间的冗余信息,sub agent 有更大更聚焦的上下文专注自身任务的执行。
上下文压缩
在生产简报这一步其实算是上下文压缩的一种策略,其移除了与用户的对话历史,让研究任务只关注于这份简报。 Research sub agent 在任务结束后,还会对过程信息进行压缩返回给到 supervisor 节点以避免 supervisor 上下文过度膨胀。
上下文剪枝
当上下文超过 LLM context 限制时,agent 会尝试下面这些剪枝策略缩减上下文来重新执行任务
# compress_research 阶段如果上下文超长则截断消息历史记录,删除到最后一条AI消息。
if is_token_limit_exceeded(e, configurable.research_model):
researcher_messages = remove_up_to_last_ai_message(researcher_messages)
continue
def remove_up_to_last_ai_message(messages: list[MessageLikeRepresentation]) -> list[MessageLikeRepresentation]:
"""Truncate message history by removing up to the last AI message.
This is useful for handling token limit exceeded errors by removing recent context.
Args:
messages: List of message objects to truncate Returns:
Truncated message list up to (but not including) the last AI message """ # Search backwards through messages to find the last AI message for i in range(len(messages) - 1, -1, -1):
if isinstance(messages[i], AIMessage):
# Return everything up to (but not including) the last AI message
return messages[:i]
# No AI messages found, return original list
return messages
# final_report_generation 阶段每次尝试删减 10% 的上下文
if is_token_limit_exceeded(e, configurable.final_report_model):
current_retry += 1
if current_retry == 1:
# First retry: determine initial truncation limit
model_token_limit = get_model_token_limit(configurable.final_report_model)
if not model_token_limit:
return {
"final_report": f"Error generating final report: Token limit exceeded, however, we could not determine the model's maximum context length. Please update the model map in deep_researcher/utils.py with this information. {e}",
"messages": [AIMessage(content="Report generation failed due to token limits")],
**cleared_state
}
# Use 4x token limit as character approximation for truncation
findings_token_limit = model_token_limit * 4
else:
# Subsequent retries: reduce by 10% each time
findings_token_limit = int(findings_token_limit * 0.9)
# Truncate findings and retry
findings = findings[:findings_token_limit]
continue
Memory
目前该项目没有使用到长期(外部)记忆 机制。Deep Research 这类项目目前基本以对话加一次性任务的形式呈现,没有太多引入长期记忆的需求。如果做成平台,需要结合用户偏好、历史报告等特性时才有接入长期记忆的必要性。
ROMA
TODO
Tongyi
TODO
-- End --